如何使用N8N來建立一個自動化部落格訂閲系統
N8N是什麽
n8n 是一個開源的自動化工作流程平台,讓用戶可以透過圖形化介面(拖拉節點)來串接和自動化各種工具、平台與服務,無需寫程式也能輕鬆建立自動化流程(雖然我的這個要寫不少JS跟SQL就對了)。
像是下面的圖片,有許多的節點跟綫條連接,這樣做的好處就是可讀性高,以及維護容易。
主要特點
- 開源免費:n8n 完全開源,任何人都可以免費下載、使用、修改,並根據需求自行部署在本地或雲端。
- 視覺化操作:只需拖拉節點、設定參數,就能設計複雜的自動化工作流,適合沒有程式基礎的使用者。
- 高度彈性與擴充性:支援自訂節點、腳本(如 JavaScript),也能安裝社群第三方擴充,適合開發者進行進階自動化。
- 豐富的整合能力:內建超過200~400種第三方應用整合(如 Google Apps、Slack、Trello、GitHub、AWS、Notion、LINE、Shopify 等),可滿足各式自動化需求。
- 自我託管:用戶可選擇將 n8n 部署在自己的伺服器,完全掌控資料安全與隱私
爲什麽需要N8N?
先想清楚:什麼事值得自動化?
- 重複性高:每天、每週都要做的瑣事。
- 很花時間:不是難,但就是煩、耗時。
- 流程固定:步驟一樣、邏輯清楚。 訂閲系統就符合以上所有需求
如何開始使用n8n
你可以使用:
- https://n8n.io/:官方的托管伺服器
- 本地端伺服器
- 其他部署平臺:本次使用hugging face 的spaces來建立。
這邊給你們一個建立hugging face的youtube影片當作參考,作者講的非常簡單明瞭,推薦!
這個方式比較適合個人專案或者是個人網站,如果需要大量使用的話就不太適合
爲什麽要自己建立一個n8n的訂閲管理系統?網路上不是有現成的?
在我開始要做這個訂閲系統管理的時候,其實遇到的問題並不是技術問題,而是有太多現成的服務,限制太多了! 像是我一開始要使用
- EmailJS
雖然他有直接提供模板,并且也有免費專案,但是他給的request數量有夠少
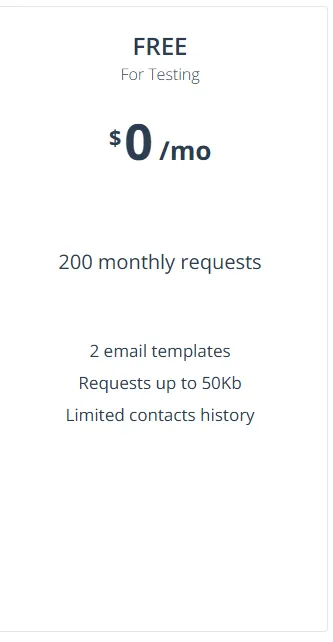
只有 200 per month!! 也就是一天發個 6 封信就沒了。
又或者是
- Mailgun 試用期短的可憐,所以我思來想去(其實就是窮),想到之前在github很早就starred,但是一直沒有真的去動手的 N8N 。
如何建立屬於自己的訂閲系統
先看這張圖
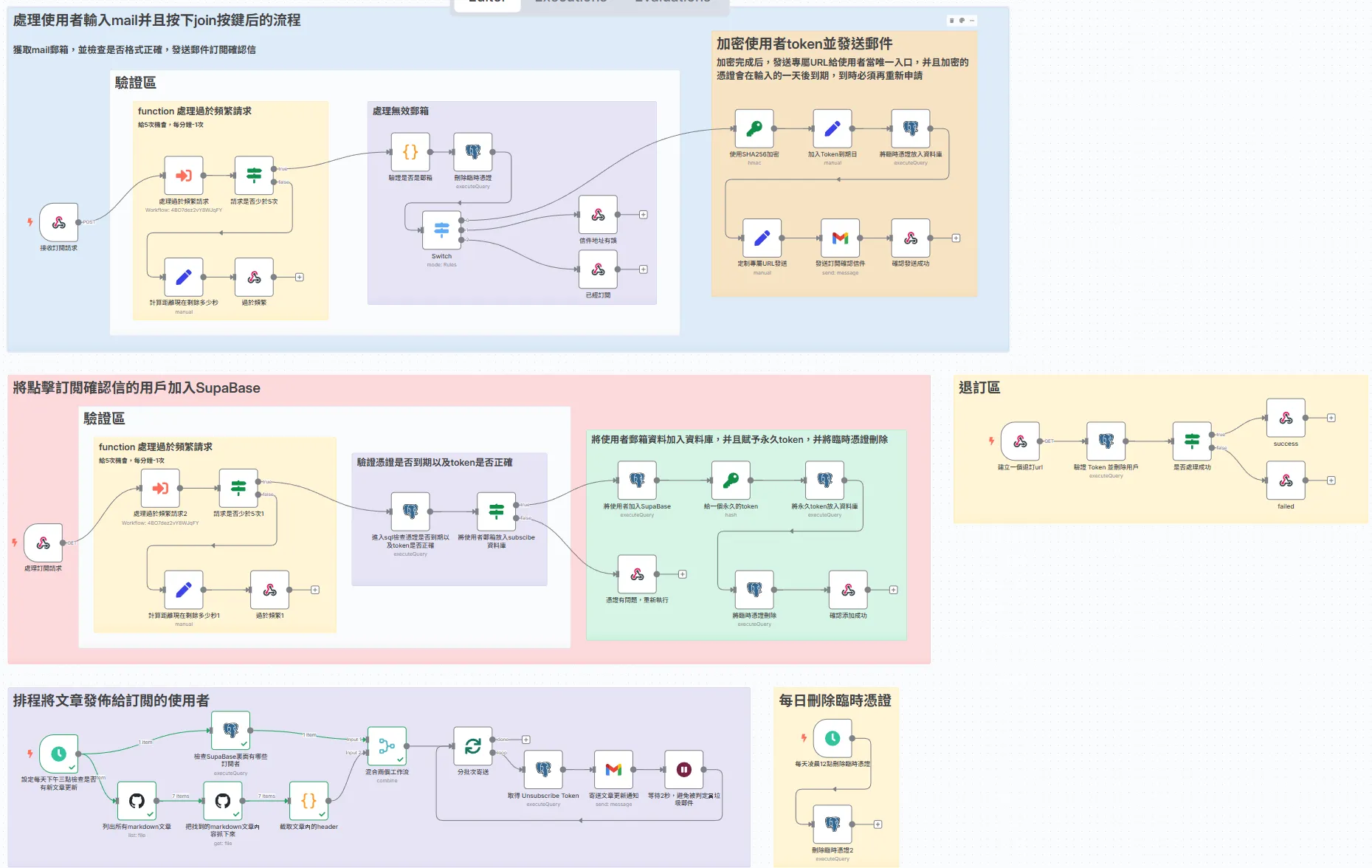 這個是我完整的流程圖,或許一開始看會非常的疑惑這個在幹嘛,不過把他每一個功能跟步驟拆解就簡單了。
這個是我完整的流程圖,或許一開始看會非常的疑惑這個在幹嘛,不過把他每一個功能跟步驟拆解就簡單了。
處理使用者輸入mail並按下join後的流程
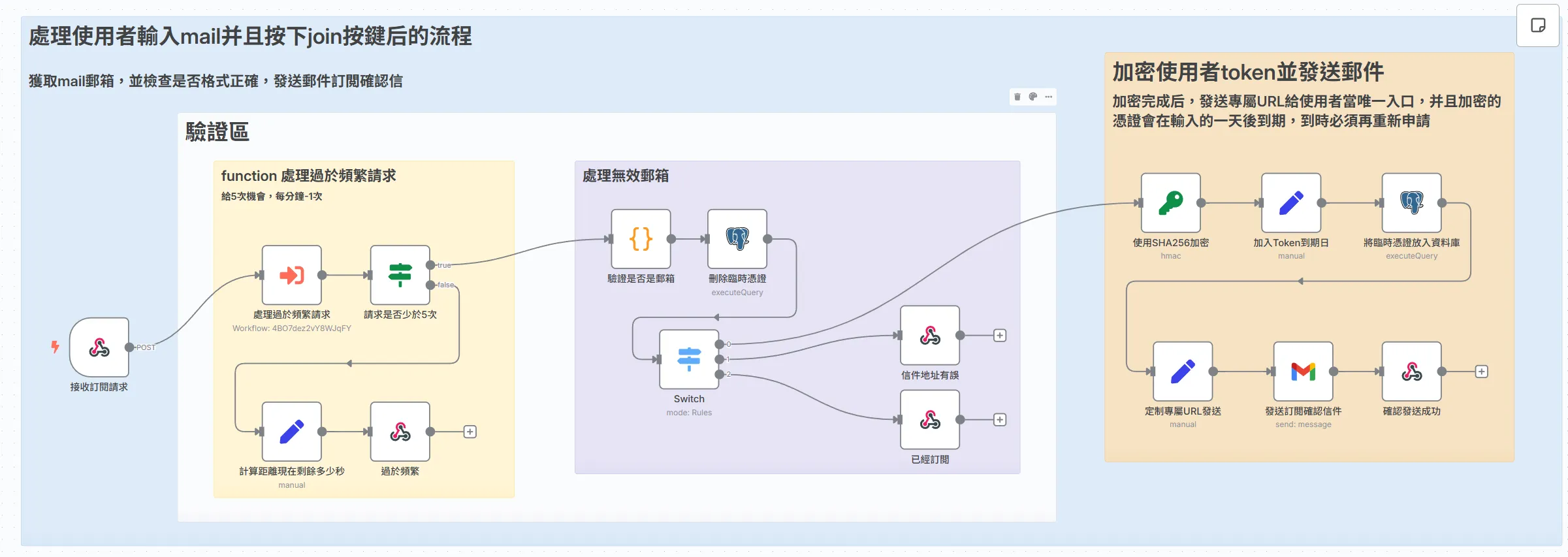
整個流程的核心思想是「先驗證,後執行」。在我們執行任何核心操作(如產生 Token、發送郵件)之前,請求必須通過三道主要的驗證關卡。只有全部通關的「優質請求」,才有資格進入下一步。 這三道關卡分別是:
- 第一道防線:IP 限速 - 抵擋惡意攻擊與爬蟲。
- 第二道關卡:多重驗證 - 確保 Email 格式正確,且非重複訂閱。
- 最終確認:發送臨時憑證 - 透過雙重驗證 (Double Opt-In) 確保信箱的真實所有權。
最左邊的接受訂閲請求,是一個webhook節點。
Webhook 節點在 n8n 中的主要功能是作為觸發器,接收來自外部系統的即時 HTTP 請求,並啟動你的自動化工作流程。
設定一個url,https://tommypan.me/webhook/subscribe (這是範例,並不存在), 只要這個url被呼叫了(像是在瀏覽器輸入),那這個url就被觸發了,這個工作流就啓動。
那通常會一起携帶一些參數一起送給這個url,在我的實作中,是跟email一起送入。
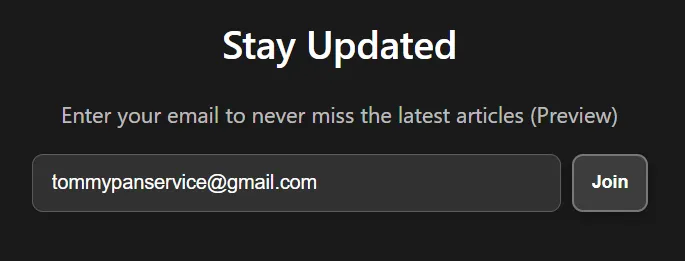 圖片可以看到,會帶著mail后按下join按鍵一起送到https://tommypan.me/webhook/subscribe
那麽我的這邊就會有你的mail,以及你一起送過來的一些基礎資訊,像是IP等等。
圖片可以看到,會帶著mail后按下join按鍵一起送到https://tommypan.me/webhook/subscribe
那麽我的這邊就會有你的mail,以及你一起送過來的一些基礎資訊,像是IP等等。
1.第一道防線:IP 限速 (Rate Limiting)
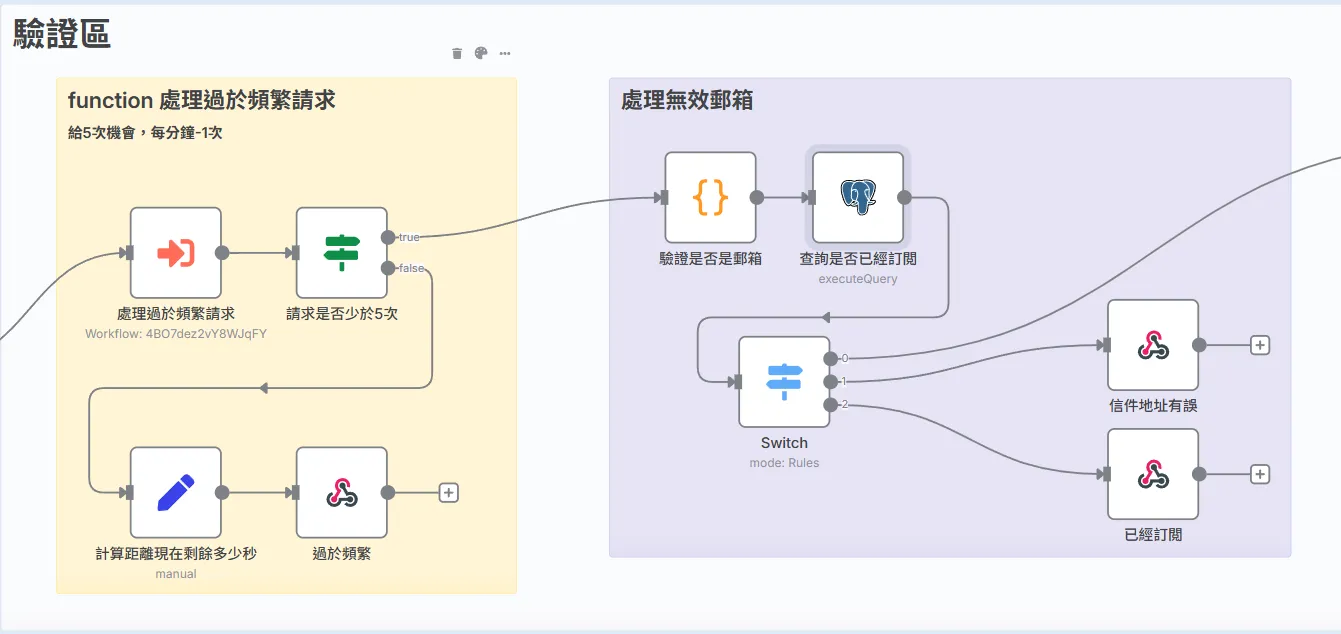 我把處理過於頻繁的請求直接寫入一個subworkflow,之後如果要使用就呼叫這個subworkflow就好了。
簡單講述這個驗證區的功能。
我把處理過於頻繁的請求直接寫入一個subworkflow,之後如果要使用就呼叫這個subworkflow就好了。
簡單講述這個驗證區的功能。
處理過於頻繁的請求:
一開始送進來的資料有附上ip,那爲了防止一些很無聊的人的一個攻擊,像是瘋狂按join按鍵,那這邊就需要一個限制,我的限制方法是每個人會有5次請求的機會,只要用完了就要等待60秒,這個請求機會的次數才會+1,當然,這個部分因人而異,不一定要跟我一樣。
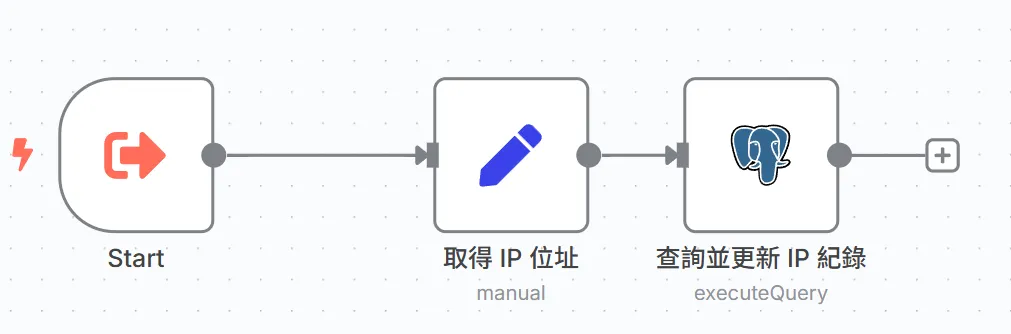 那要如何做呢?
如果你有看前面的youtube影片了話,就知道有一個免費的資料庫叫做supabase,那我要建立一個表格,來存放使用者的資訊。
其中postgres節點就是處理資料庫的節點。
我會需要這些資料:
那要如何做呢?
如果你有看前面的youtube影片了話,就知道有一個免費的資料庫叫做supabase,那我要建立一個表格,來存放使用者的資訊。
其中postgres節點就是處理資料庫的節點。
我會需要這些資料:
 request_tokens總數是5,因爲我設定5次請求機會,這個會隨著你瘋狂點擊join按鍵之後減少,當減少到0之後,就會鎖住,那就是locked_until要做的事情了。
request_tokens總數是5,因爲我設定5次請求機會,這個會隨著你瘋狂點擊join按鍵之後減少,當減少到0之後,就會鎖住,那就是locked_until要做的事情了。
locked_until要做的事就是會在last_request_at的時間加1分鐘,那麽隨著你每一次的點擊,都會記錄locked_until-last_request_at時間過後的秒數,當小於0就可以重新按join按鍵。 這個做法避免了許多有心人士的胡搞瞎搞,也保有了一定的彈性。
2. 第二道關卡:多重驗證
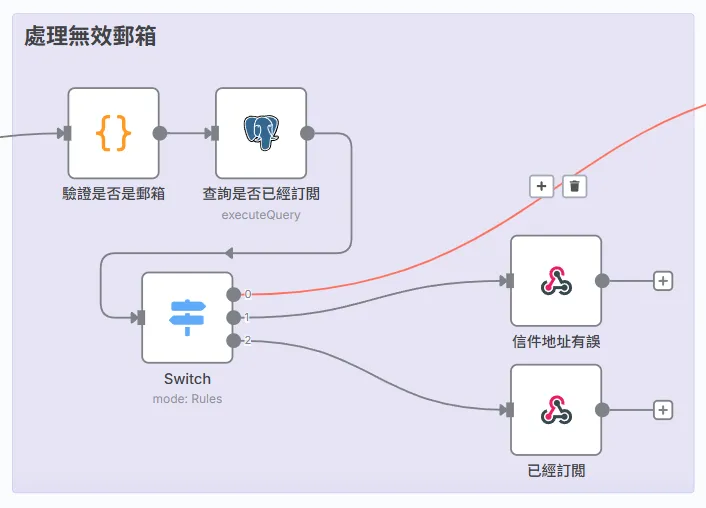
- 處理無效信箱:
這個做法就很直觀,篩選到可能不是信箱的格式,并且查詢是否這個郵箱已經在訂閲的資料庫了(這個之後會講),然後依據條件給幾個路徑,分別處理不同事件。 - 查詢是否已經訂閱 (Postgres 節點):
查詢我們正式的 subscribers 資料庫,確認這個 Email 是否已經是有效訂閱者。

- 分流 (Switch 節點):
這就像一個交通指揮中心。它根據前面兩步的驗證結果,將請求導向三個不同的出口:
- 路徑 0 (新用戶):
格式正確且資料庫中不存在,這是我們期望的路徑,可以繼續訂閱流程。 - 路徑 1 (格式錯誤):
Email 格式不正確,流程終止,回傳「信件地址有誤」。 - 路徑 2 (已訂閱):
Email 格式正確,但在資料庫中已存在,流程終止,回傳「已經訂閱」。
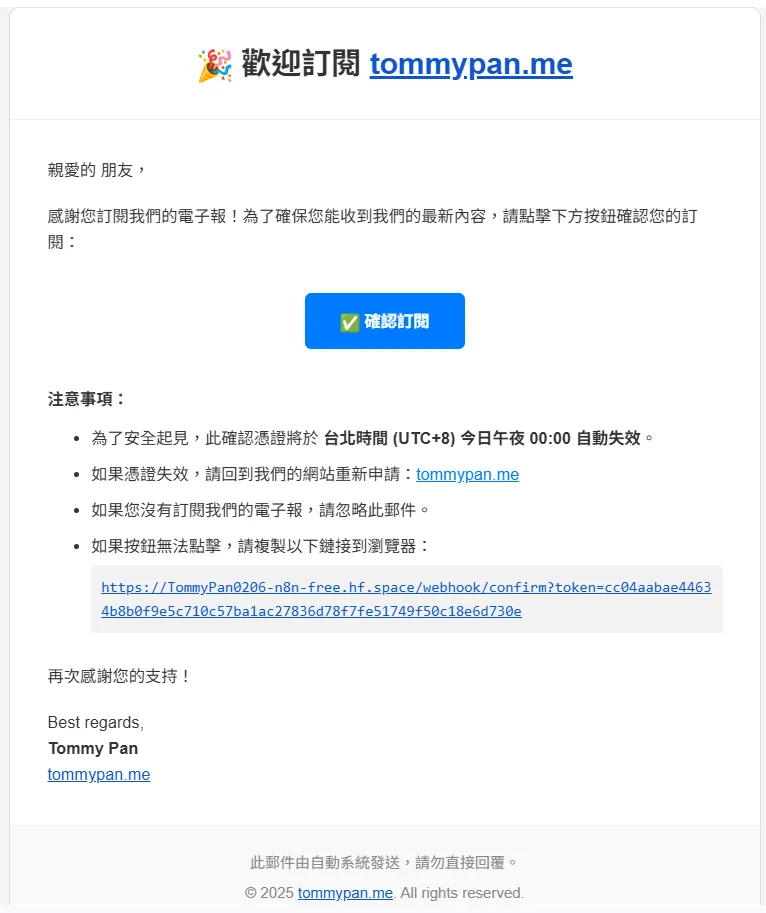
那我的回傳是將message帶著進入指定的URL,我設定的是tommypan.me/respound?message=[your_text]。 我會帶著這個資訊到指定的分頁並顯示出來,如下圖: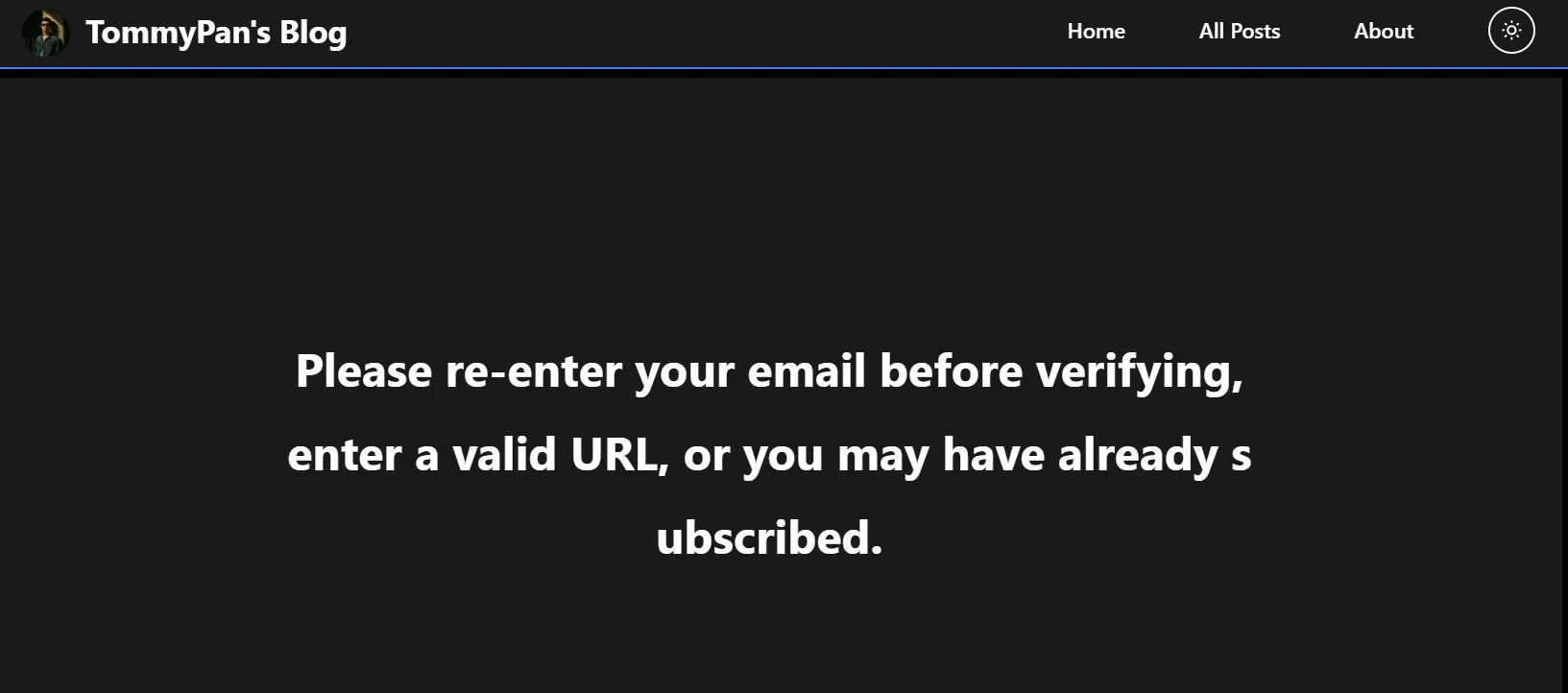 這個就是在帶著這段文字出現在我指定的分頁的結果,當然,背後的html的設計還是要自己思考(或跟我一樣叫AI思考)。
這個就是在帶著這段文字出現在我指定的分頁的結果,當然,背後的html的設計還是要自己思考(或跟我一樣叫AI思考)。
3. 最終確認:發送臨時憑證 - 透過雙重驗證 (Double Opt-In) 確保信箱的真實所有權。
對於一個全新的、合法的訂閱請求,我們進入了最後一步:雙重驗證 (Double Opt-In)。
我們不會立刻將用戶加入訂閱列表,而是先發送一封確認信,要求他們點擊連結來證明自己是該信箱的所有者。
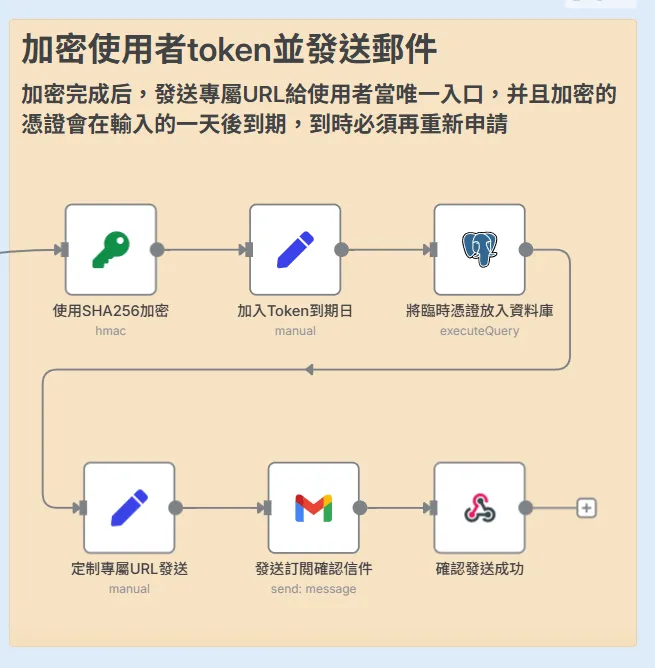
- 產生加密 Token (Crypto 節點):
使用 SHA256 演算法,將「用戶 Email + 當下時間戳」進行雜湊,產生一個獨一無二且難以偽造的臨時 Token。 - 設定到期日 (Set 節點):
為這個 Token 設定一個 24 小時的過期時間。 - 存入臨時資料庫 (Postgres 節點):
將這個 token、email 和 expires_at 存入一個名為 pending_confirmations 的暫存資料表中。

- 發送確認信 (Gmail 節點):
建立一個包含此 Token 的專屬確認 URL (…/confirm?token=xxx),並將其放入精美的郵件範本中發送給使用者。 - 回應前端 (Respond to Webhook 節點):
最後,向用戶的前端頁面回傳一個成功訊息,告訴他們:「確認信已發送,請查收郵件!」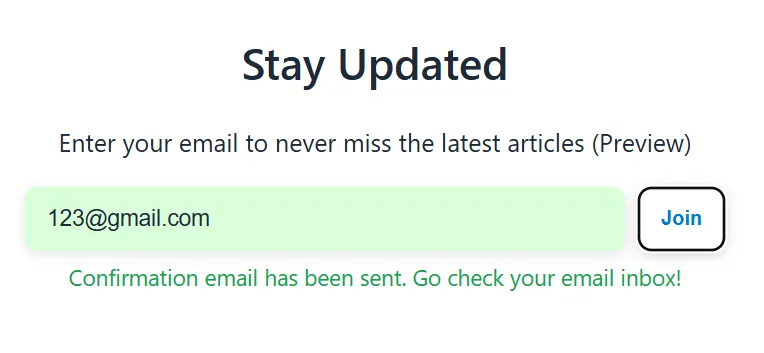
將點擊訂閲確認信的用戶加入SupaBase
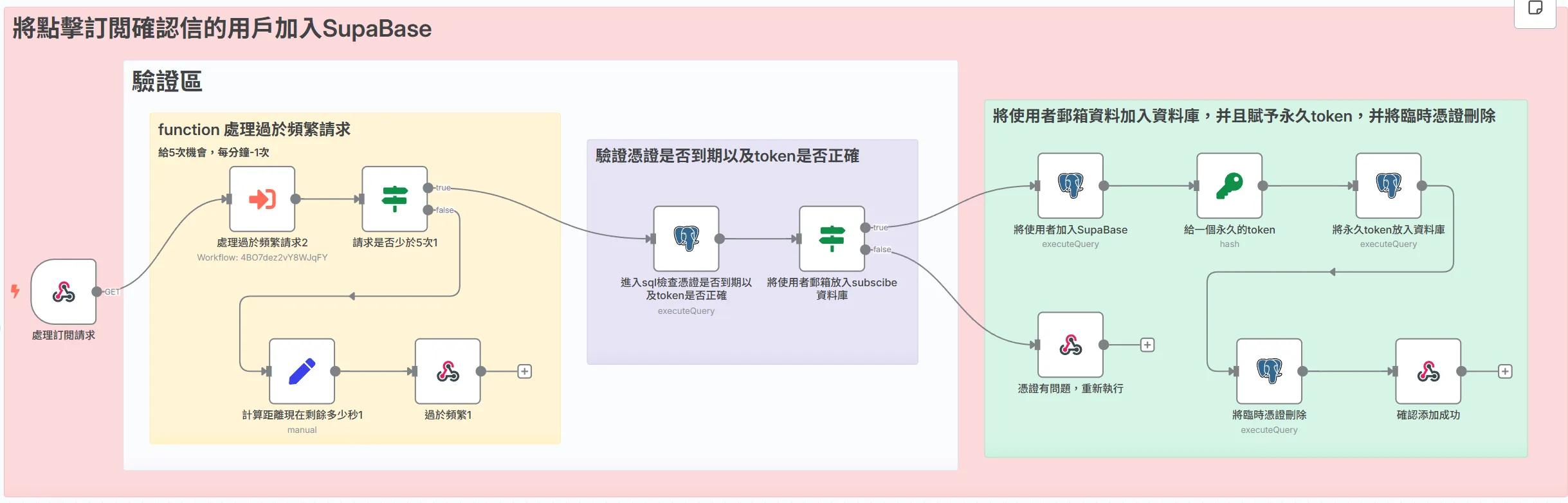
驗證區塊
1.處理過於頻繁請求:這部分跟前面一樣,就不多贅述
2.憑證有效性檢查 (Token Validation)
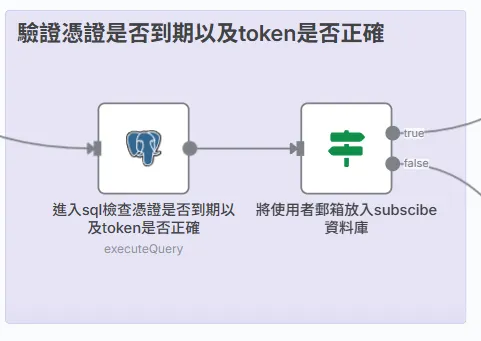
這是整個流程的核心驗證環節。當使用者點擊連結 (…/confirm?token=xxx) 時,我們拿到了這個 token,然後立刻去 pending_confirmations 暫存資料表中進行核對。
SELECT email FROM pending_confirmations
WHERE token = $1 AND expires_at > NOW();
這句 SQL 會同時檢查兩件事:
- 傳來的 Token 是否存在於我們的暫存表中?
- expires_at > NOW():這個 Token 是否還在 24 小時的有效期內?
分流處理 (If 節點):
只有當上面的查詢有且僅有一筆結果時,才代表這是一次合法、有效的確認請求,流程才會走向 True 分支。任何查詢不到結果的情況(Token 錯誤、已使用或已過期),都會被導向 False 分支,並向用戶顯示「連結無效或已過期」的頁面。
將使用者郵箱資料加入資料庫,并且賦予永久token,并將臨時憑證刪除
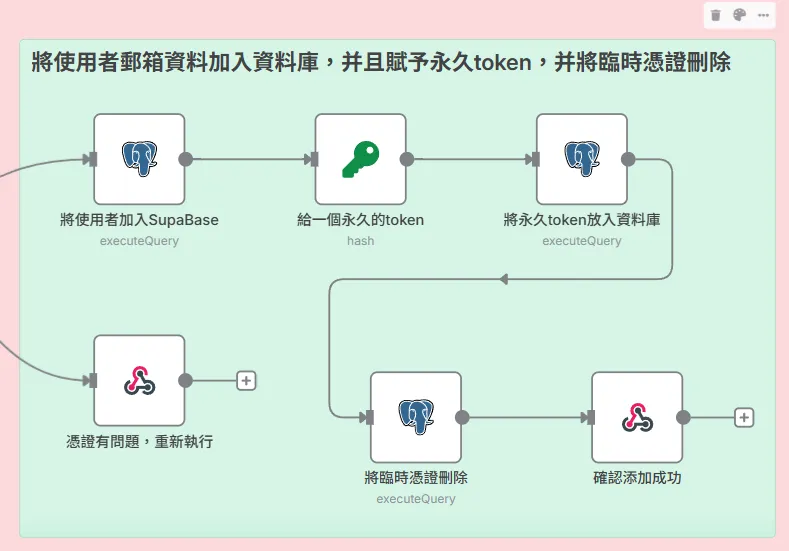
一旦請求通過了所有驗證,就意味著一位新的訂閱者即將誕生。接下來的步驟,就是為他完成正式的「入籍」手續。
1. 將使用者加入 SupaBase (正式註冊):
我們將從臨時表中查到的 email 寫入正式的 subscribers 資料庫。這句語法的好處是,它能自動處理「新用戶插入」和「已退訂用戶重新確認」兩種情況,確保資料庫的整潔。
2. 給一個永久的 Token (簽發身份證):
這是為了未來的「退訂」功能做準備。我們不希望退訂連結中包含用戶的 Email 等敏感資訊。因此,在用戶確認的這一刻,我們為他產生一個專屬的、永久的退訂 Token。
- 實現邏輯 (Crypto 節點): 使用 SHA256 演算法進行雜湊。
- 存入資料庫:
接著,用 UPDATE 語句,將這個新產生的 unsubscribe_token 存入該用戶在 subscribers 表中的對應欄位。
3. 將臨時憑證刪除 (銷毀臨時文件):
這是安全流程的最後一環,也是至關重要的一步。
在確認用戶已成功註冊並獲得永久 Token 後,我們必須立即回到 pending_confirmations 暫存表中,將這次使用的臨時 Token 刪除。
4. 確認添加成功:
所有後台操作完成後,我們向用戶的瀏覽器回傳一個「歡迎!您已成功訂閱」的頁面。
排程將文章發佈給訂閲的使用者
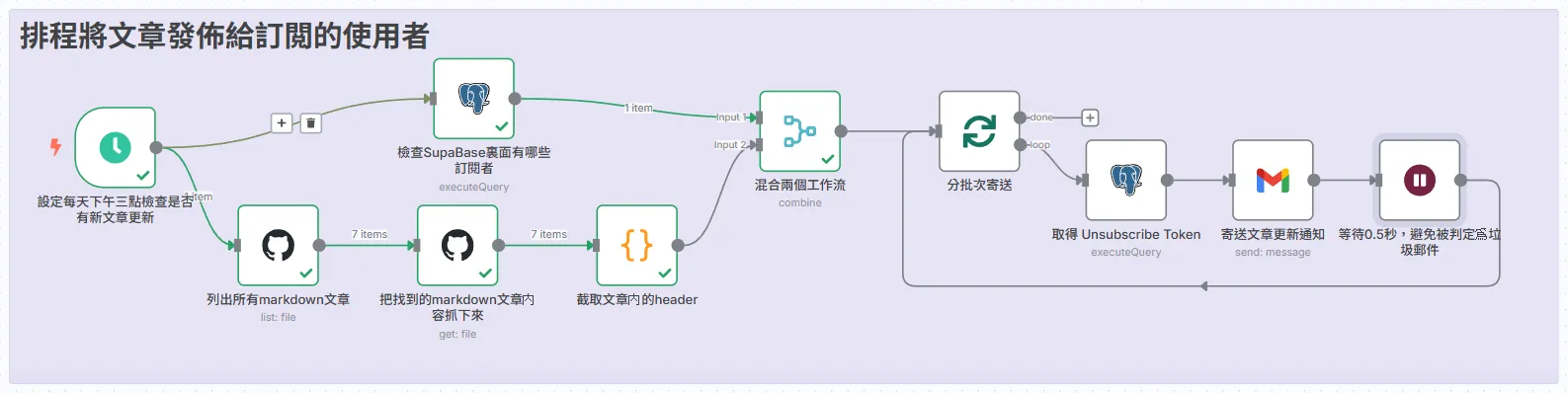 在這之前,我們已經建立了訂閱和確認流程,現在,是時候讓這個系統實現它的核心了:發送內容。
這個流程的設計,可以拆解為三個核心階段:
在這之前,我們已經建立了訂閱和確認流程,現在,是時候讓這個系統實現它的核心了:發送內容。
這個流程的設計,可以拆解為三個核心階段:
- 內容聚合:從哪裡獲取今天的文章?
- 受眾聚合:今天要寄給哪些人?
- 智慧投遞:如何貌地完成投遞?
1. 内容聚合
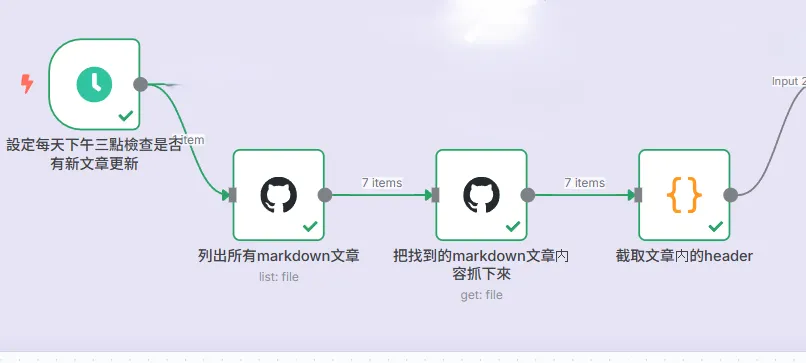
既然我的部落格是託管在 GitHub 上的,那麼「新文章」的唯一真實來源就是我的 Git 倉庫。這個流程的第一步,就是化身為一個自動化的偵察兵,去 GitHub 倉庫裡尋找昨天發佈的新文章。
1. 設定鬧鐘 (Schedule Trigger 節點):
- 工作流的起點是一個排程觸發器。我將它設定為「每天下午三點」自動啟動。
2. 掃描文章目錄 (GitHub 節點 - list: file):
- 流程啟動後,它會立刻透過 API 連接到我的 GitHub 倉庫,直接掃描存放所有 Markdown 文件的 /content/posts/ 目錄。
3. 抓取文章內容 (GitHub 節點 - get: file):
- 它會遍歷目錄中的每一篇文章,並將其完整的 Markdown 內容抓取下來。
4. 截取文章内的header (Code 節點):
- 這是最關鍵的一步。這個 Code 節點就像一個精密的剖析器,它會對每一篇抓取到的 Markdown 內容做幾件事:
- 解碼內容: 將從 GitHub API 獲取的內容解碼回人類可讀的 Markdown 文本。
- 提取 Front Matter: 使用正規表示法,精準地抓取出文章頭部的元數據區塊 (被 +++ 包裹的部分)。
像是我的其中一篇文章的fornt matter長這樣:
+++
title = '使用 Gradio MCP 建立伺服器,并部署在Hugging Face Space'
date = '2025-06-23T10:00:00+08:00'
draft = false
description = '使用Gradio MCP 建立情感分析伺服器,并且一并部署在Hugging Face Spaces上,以利後續實現'
tags = ['MCP Server', 'LLM', 'AI','Hugging Face','Gradio']
categories = ['技術']
author = 'Tommy Pan'
image = 'images/MCP-CH5/1.webp'
+++
- 日期比對:
從元數據中提取 date 欄位,並將其與「昨天」的日期進行比對。只有日期完全符合的文章,才有資格被繼續處理。 - 提取關鍵資訊:
對於通過日期驗證的文章,它會繼續提取 title, description, tags, categories, image 等所有我們需要的欄位。 - 格式化輸出:
最後,將所有提取出的資訊,整理成一個標準化的 JSON 物件,傳遞給下一個節點。
2. 受眾聚合
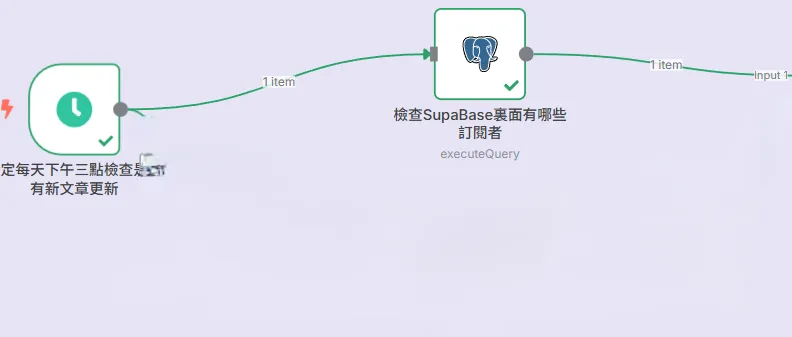
知道了今天要寄送什麼內容,下一步自然是搞清楚要寄給誰。
- 檢查 SupaBase 訂閱者 (Postgres 節點):
工作流會並行地執行另一項任務:查詢我們的 subscribers 資料庫,獲取所有 is_confirmed = TRUE 的用戶列表。最重要的是,我們在這個查詢中,會一併將他們各自的永久 unsubscribe_token 也查詢出來。
3. 投遞信件
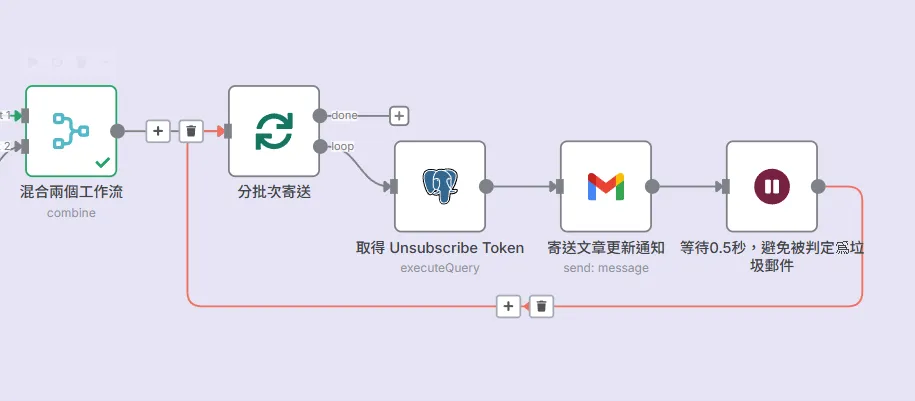
現在,我們手上有兩份清單:一份是「今天的文章」,另一份是「今天的收件人名單」。接下來就是把它們組合起來,並開始投遞。
1. 混合兩個工作流 (Merge 節點):
Merge 節點在這裡扮演了關鍵的組合角色。它會將「文章數據」和「所有訂閱者數據」進行笛卡爾積組合,產生一個最終的發送列表。例如,如果有 1 篇新文章和 100 個訂閱者,它就會產生 100 個待辦項目,每個項目都包含了文章的完整資訊和一位訂閱者的 Email 及退訂 Token。
2. 分批次寄送 (Split In Batches 節點):
直接一次性發送成百上千封郵件,很容易被郵件服務商(如 Gmail)判定為垃圾郵件發送行為。為了避免被封鎖,Split In Batches 節點會將龐大的發送列表拆分成小批次,例如每批只處理一封郵件。
3. 循環投遞 (Loop):
這個節點會開始一個循環,逐一處理上一批次中的每一封郵件。 寄送文章更新通知 (Gmail 節點): 在這個循環的核心,Gmail 節點會使用上游傳來的數據,填充一個 HTML 郵件範本。範本中會包含文章的標題、描述、封面圖,以及最重要的,包含了該用戶專屬 unsubscribe_token 的退訂連結。
- 等待 0.5 秒 (Wait 節點): 每發送完一封郵件,流程會刻意暫停 0.5 秒。這個小小的「喘息」是在模擬人類的發送行為,進一步降低被判定為垃圾郵件的風險。
至此,我們利用 n8n 打造的電子報系統的三大核心流程——訂閱、確認、分發——已全部解析完畢。
退訂區
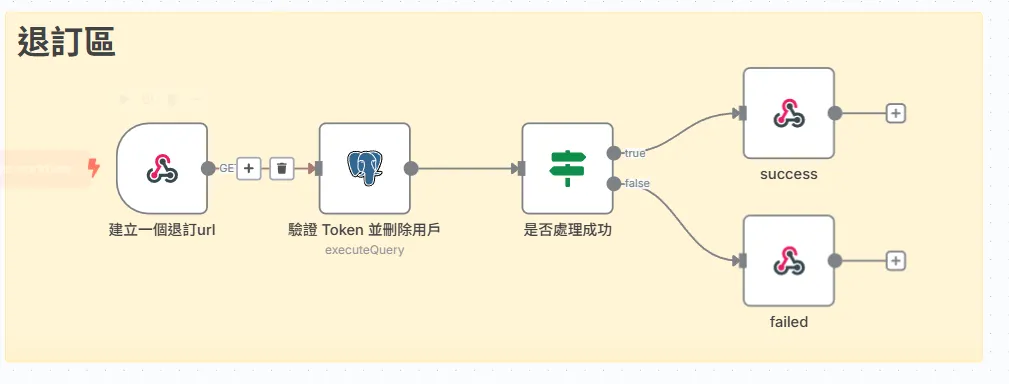 一個完整的系統,不僅要考慮如何讓用戶「進來」,更要思考如何讓他們能輕鬆、安心地「離開」。
一個完整的系統,不僅要考慮如何讓用戶「進來」,更要思考如何讓他們能輕鬆、安心地「離開」。
退訂的基石:永久且唯一的退訂 Token
在深入流程之前,我們必須重溫一個關鍵的設計:在用戶成功確認訂閱的那一刻,我們就為他產生了一個永久的、唯一的、與其 Email 綁定的 unsubscribe_token,並儲存在了 subscribers 資料庫中。 這個設計是整個退訂流程能夠做到既安全又方便的核心。
安全:退訂連結中只包含這個無意義的 Token (…/unsubscribe?token=xxx),完全不會暴露用戶的 Email 地址。
1. 建立一個退訂 URL (Webhook 節點):
這是退訂流程的唯一入口。它被設定為監聽一個特定的路徑,例如 /webhook/unsubscribe。 當用戶點擊郵件中的退訂連結時,這個 Webhook 會被觸發,並從 URL 的查詢參數中,捕獲到那個獨一無二的 token。
2. 驗證 Token 並處理用戶 (Postgres 節點):
這是流程的核心操作。我們拿到 token 後,會立刻去 subscribers 資料庫中執行刪除。
3. 判斷是否處理成功 (If 節點):
這個 If 節點的條件非常簡單:{{ $node[“驗證 Token 並刪除用戶”].json.length > 0 }} 它會檢查上一步的 SQL 操作,是否有返回任何數據。
- True 分支 (處理成功): 如果返回的數據長度大於 0,意味著 UPDATE 語句成功地找到並更新了一筆資料。這說明傳來的 token 是有效的。
- False 分支 (處理失敗): 如果返回的數據長度為 0,意味著 UPDATE 語句沒有找到任何匹配 unsubscribe_token 的資料。這可能是因為 Token 錯誤,或是用戶已經退訂過了。
4. 回應使用者 (Respond to Webhook 節點):
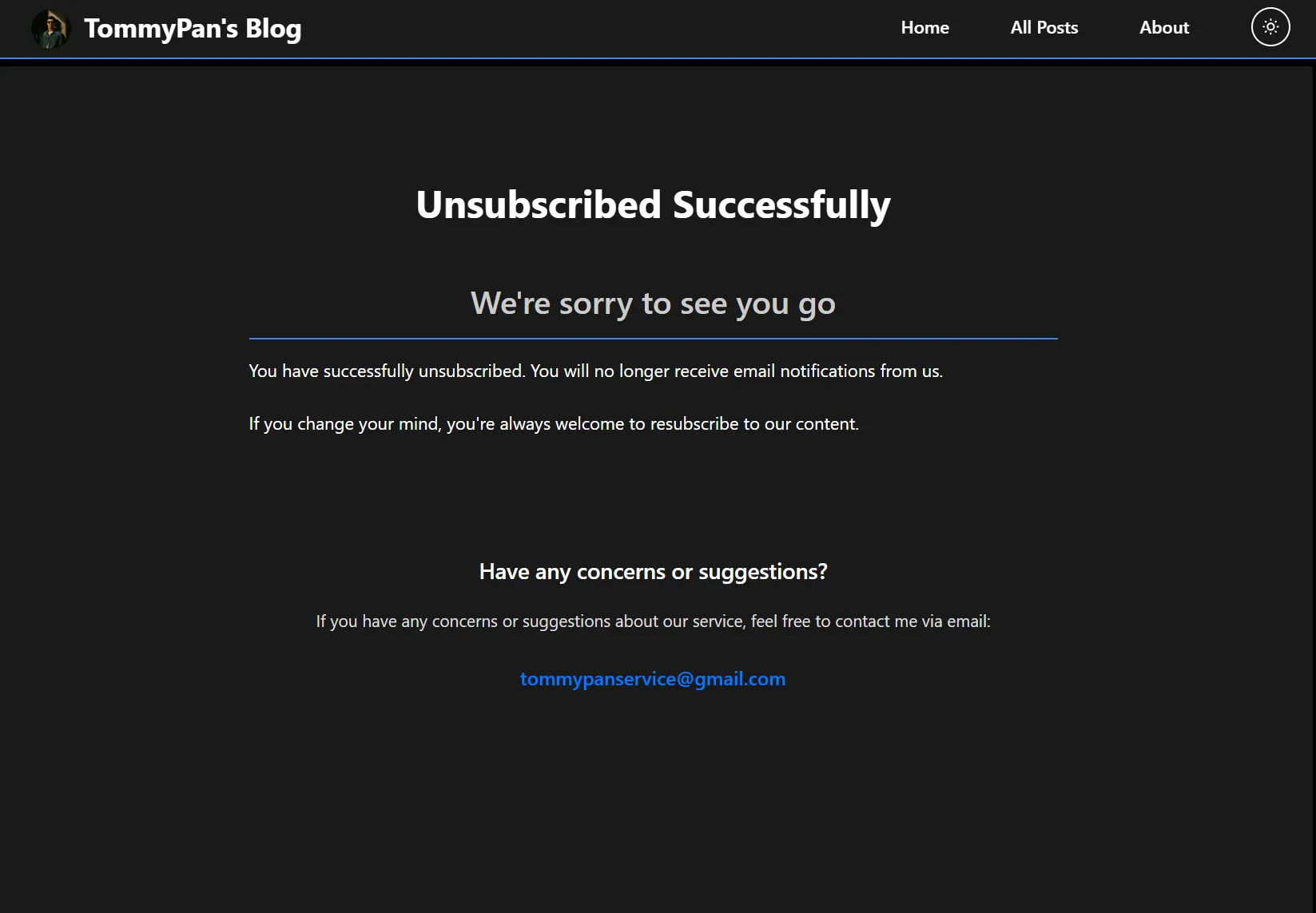
根據上一步的判斷結果,我們向用戶的瀏覽器回傳一個清晰的 HTML 頁面。
每日刪除臨時憑證
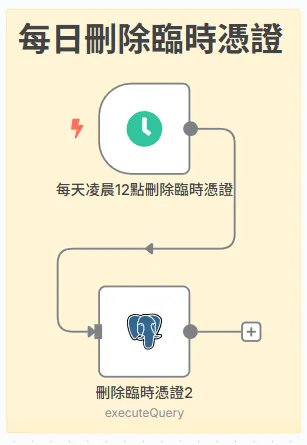
在我們設計的整個電子報系統中,有一個特別的資料表叫做 pending_confirmations。它的作用是暫時存放那些已經發出、但用戶尚未點擊確認的臨時 Token。
理論上,每一個臨時 Token 都有兩種宿命:
- 被使用:用戶點擊確認連結,Token 被驗證後,立即從這個表中刪除。
- 被遺忘:用戶從未點擊確認連結,這個 Token 就會永遠地留在了資料庫裡。 如果我們對這些「被遺忘」的 Token 置之不理,隨著時間的推移,pending_confirmations 表將會變得越來越臃腫,堆積了大量無用的、早已過期的數據。這不僅會佔用儲存空間,還可能在未來拖慢資料庫的查詢效能。
到此爲止,我已經解析了所有的内容了
其實在開發這個n8n的時候,雖然説n8n標榜0程式碼,但是如果要進階使用了話,還是要參雜不少程式碼來使用,像是SQL的操作,以及部分的Javascript的使用,對於初學者來説還是會有門檻在,但是N8N的好處就是已經收錄了很多的元件,像是GMAIL發送,只要設定好賬號以及HTML之後,一個節點就能發送GMAIL了,真的很方便,并且在這之中體驗到了N8N自動化的强大,以及對於許多產業的冲擊。
還有什麽沒做好
流程優化:
老實説,如果你真的有發送訂閲請求了話,能夠感受到從點擊到收到回饋的時間有一點久,或許是因爲我的workflow都是使用串接的方法,所以每一個節點都必須要等上一個節點的輸入,才有辦法繼續做事。
這個就很花時間,并且在我的觀察下,其實執行SQL查詢的時候才是吃掉最多時間的,因爲supaBase的伺服器是放在跟n8n不同的位置,雖然我都把地區選擇在北加州,但是或許他們交互的時間本身就有一定開銷(免費仔還能要求什麽)。
所以之後的優化方向或許是將驗證區的驗證改成并行,這樣在每一次查詢資料庫的時候,或許就可以節省掉不少的時間,使用者體驗就會比較好。更聰明的文章讀取:
再來就是github列出所有文章并且把找到的文章内容抓下來讀取format header的部分,在文章少的時候或許還吃得消,但是文章量一大的時候,就會導致花費大量時間在下載文章跟讀取header的時間。
雖然説如果都交給自動化了話或許不是大問題,可能你會晚個1-2兩分鐘收到信件,但是對於系統優化的方面,還是有很大的進步空間。如何處理郵件送到垃圾信箱:
最後就是要處理我的我的信件或許會被分類到垃圾信件當中,這個就很尷尬,因爲這個評斷標準並不是在我這邊,也不是完全的透明,不過如果做好文章内容,然後送出的文章被開啓率高了話,或許這個就可以改善。
總結
我是用N8N來打造了一個專屬於自己的訂閲系統,其中包含了處理
- 處理使用者輸入mail并且按下join按鍵后的流程
- 將點擊訂閲確認信的用戶加入SupaBase
- 排程將文章發佈給訂閲的使用者
- 退訂功能
- 每日刪除臨時憑證
在這之中學到了許多N8N的操作方式以及建立工作流,并且將我的網頁的前端後端整合起來,變成一套完整的網頁,算是蠻有成就感的,如果你對於這方面的議題也感興趣,歡迎跟我聯絡!